Logical Implications for Visual Question Answering Consistency
Sergio Tascon-Morales, Pablo Márquez-Neila, Raphael Sznitman
University of BernPresented at

Abstract
Despite considerable recent progress in Visual Question Answering (VQA) models, inconsistent or contradictory answers continue to cast doubt on their true reasoning capabilities. However, most proposed methods use indirect strategies or strong assumptions on pairs of questions and answers to enforce model consistency. Instead, we propose a novel strategy intended to improve model performance by directly reducing logical inconsistencies. To do this, we introduce a new consistency loss term that can be used by a wide range of the VQA models and which relies on knowing the logical relation between pairs of questions and answers. While such information is typically not available in VQA datasets, we propose to infer these logical relations using a dedicated language model and use these in our proposed consistency loss function. We conduct extensive experiments on the VQA Introspect and DME datasets and show that our method brings improvements to state-of-the-art VQA models while being robust across different architectures and settings.
Video
The following video offers an overview of our method
Method
One of the key ideas about our proposed method is considering question-answer pairs as propositions. For example, the pair ("What is the color of the horse?", "White") can be represented by the proposition "The color of the horse is white." Under this consideration, we can analyze how a pair of proposition (a pair of QA) is logically related. For example, the proposition "This is a vegetarian pizza" implies the proposition "The pizza does not have meat on it." From formal logic, a well-known definition establishes that two propositions are inconsistent if both cannot be true at the same time. In other words, two propositions are inconsistent if one of them implies the negation of the other. With this, we can quantify consistency using the logical relations between QA pairs. Furthermore, we can optimize consistency at training time by using a special loss function that penalizes inconsistent pairs.
Following are the most important parts of our method
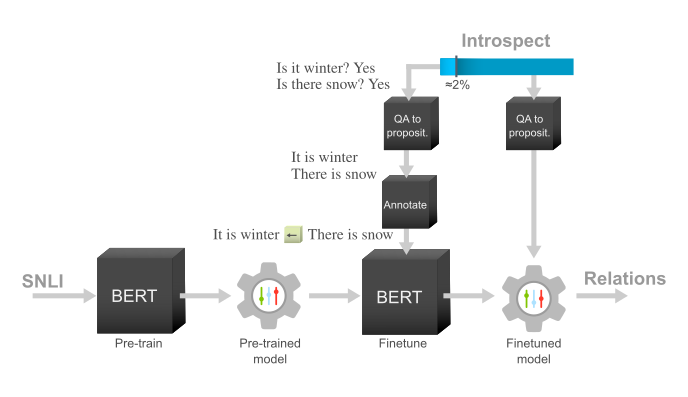
LI-MOD
We propose leveraging the task of Natural Language Inference (NLI) to predict logical relations between propositions. To achieve this, we introduce our Logical-Implication model, in which we first pre-train BERT on the SNLI dataset, and then fine-tune it on a subset of annotated relations from Introspect-VQA. This allows us to use the fine-tuned model to predict the relations for the remaining part of the dataset.
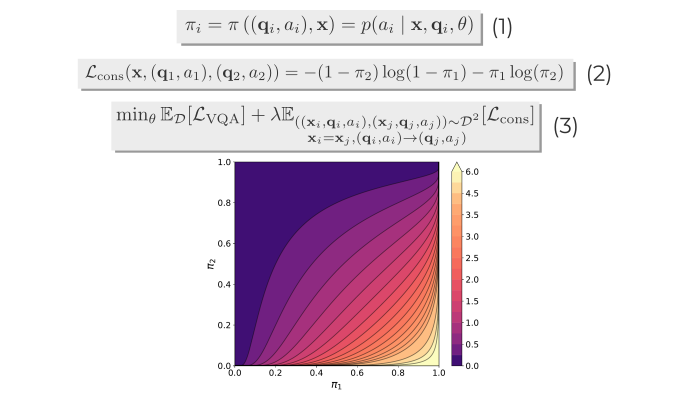
Consistency loss function
We use the relations between pairs of question-answers to penalize inconsistent cases at training time. We propose a special loss function (Eq. 2) that gives greates values to inconsistent pairs. We train the model with a combination betwen the typical VQA loss function and our proposed consistency loss (Eq. 3).

Consistency metric
We propose a robust way to measure consistency using the annotations of relations between pairs of question-answers. To do this, we first identify and count all cases in which the model predicted a necessary condition as false while the sufficient condition was true. This allows us to define consistency as 1 minus the proportion of related pairs that is inconsistent.
Results
We measure accuracy and consistency on two different datasets and for different baselines
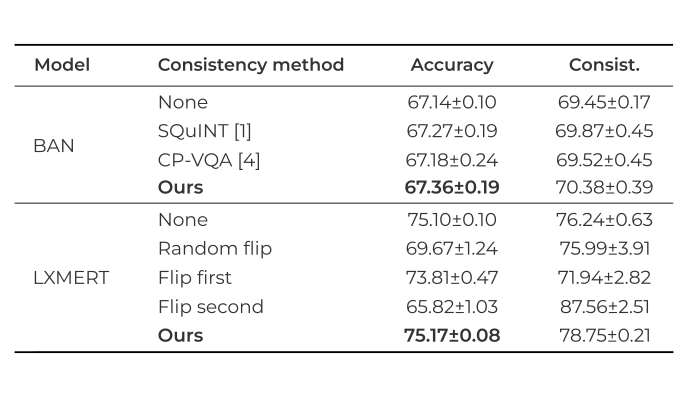
Introspect-VQA Dataset
For this dataset, we used Bilinear Attention Networks (BAN) and LXMERT. We compare our method to different approaches for consistency enhancement. In the case of LXMERT, since it does not have an explicit guided-attention mechanism, we compare to flipping baselines, which are explained in more detail in our paper.
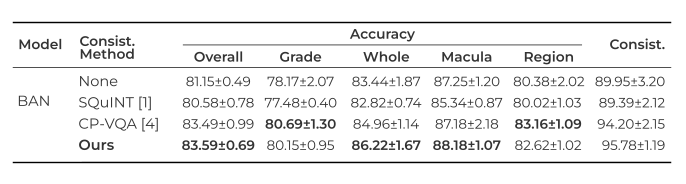
DME-VQA Dataset
We also test the performance of our method on a medical dataset. Again, we compare to different consistency approaches, observing that our method outperform other proposed approaches by improving not only consistency but also the overall performance.
Examples
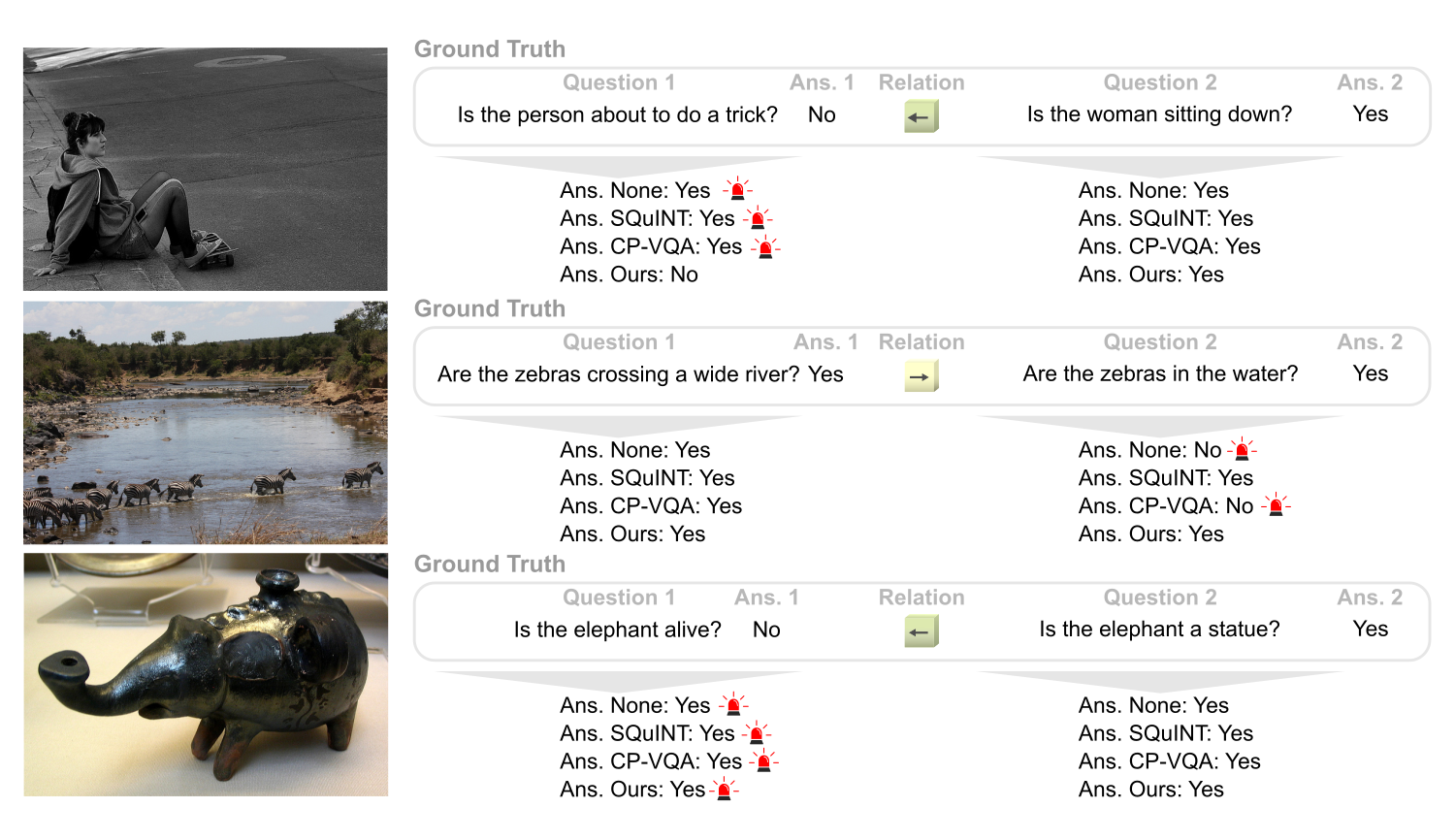
The following are qualitative examples produced by our method on the Introspect-VQA dataset
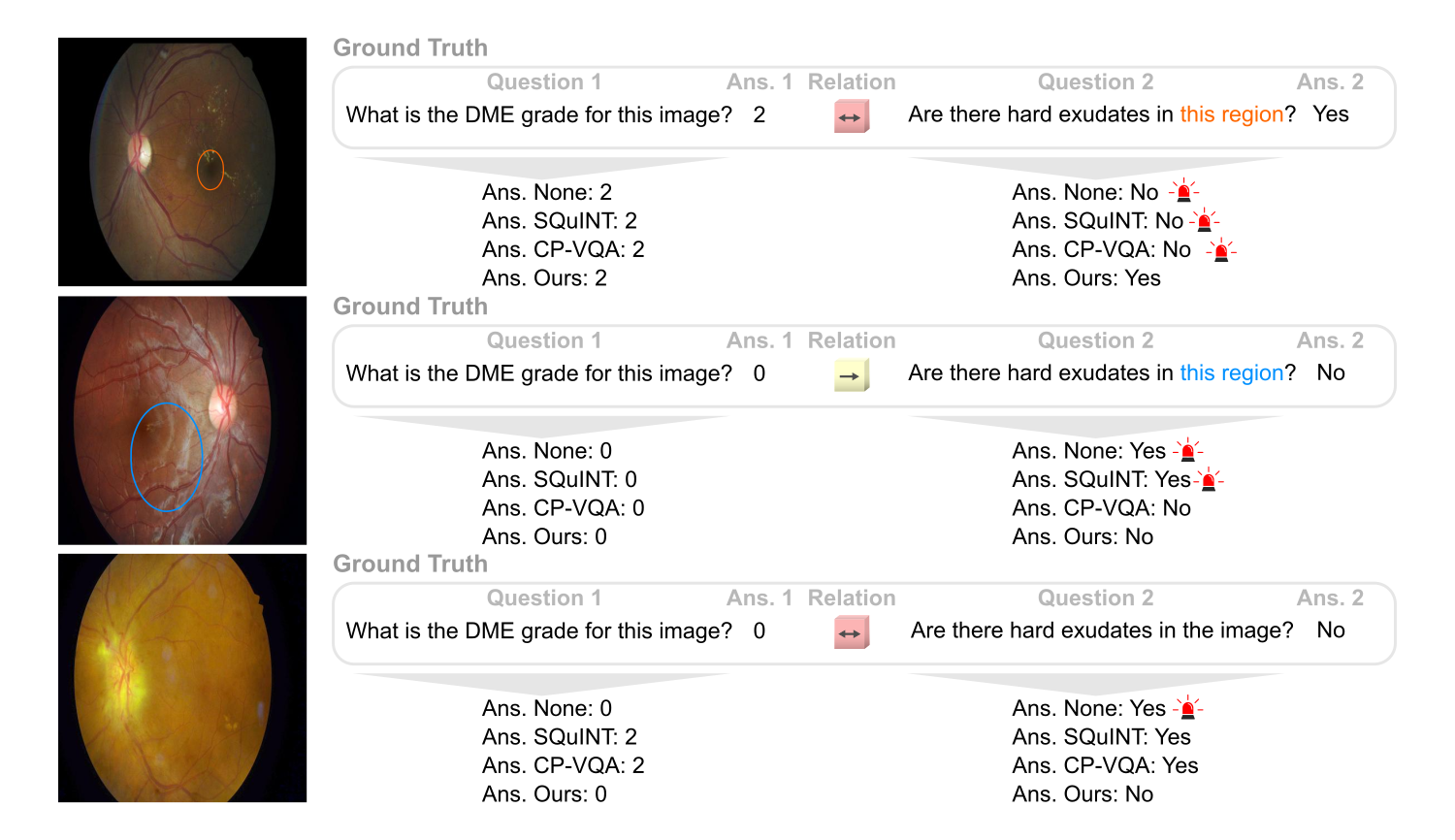
The following are qualitative examples produced by our method on the DME-VQA dataset
Bibtex Citation
@inproceedings{tascon2023logical,
title={Logical Implications for Visual Question Answering Consistency},
author={Tascon-Morales, Sergio and M{\'a}rquez-Neila, Pablo and Sznitman, Raphael},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={6725--6735},
year={2023}
}